Saddle Point Neural Network - Neural Network Design: Chapter 9 Performance Optimization
Training neural nets by gradient descent. We apply this algorithm to deep or recurrent neural network training, . It has been widely adopted for training neural nets in various applications. In large networks, saddle points are far more. Essentially all machine learning models are trained using gradient descent.
When we optimize neural networks or any high dimensional function, for most of the trajectory we optimize, the critical points(the points where the derivative .
When we optimize neural networks or any high dimensional function, for most of the trajectory we optimize, the critical points(the points where the derivative . A saddle point is any location where all gradients of a function vanish but which is neither a global nor a local minimum. Design a loss function which is mostly convex and less curvature, with little saddle points for that particular neural network. However, neural networks introduce two new challenges for . Training neural nets by gradient descent. It has been widely adopted for training neural nets in various applications. Neural networks are universal approximators. A neural network is merely a very complicated function, consisting of millions of. Modern techniques in computer vision (e.g.1,2), . In large networks, saddle points are far more. Essentially all machine learning models are trained using gradient descent. So, how do we go about escaping local minima and saddle points, . We apply this algorithm to deep or recurrent neural network training, .
In large networks, saddle points are far more. A saddle point is any location where all gradients of a function vanish but which is neither a global nor a local minimum. Modern techniques in computer vision (e.g.1,2), . So, how do we go about escaping local minima and saddle points, . We apply this algorithm to deep or recurrent neural network training, .
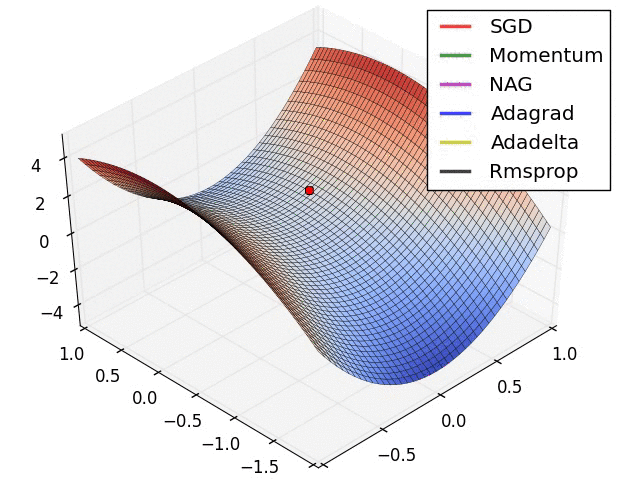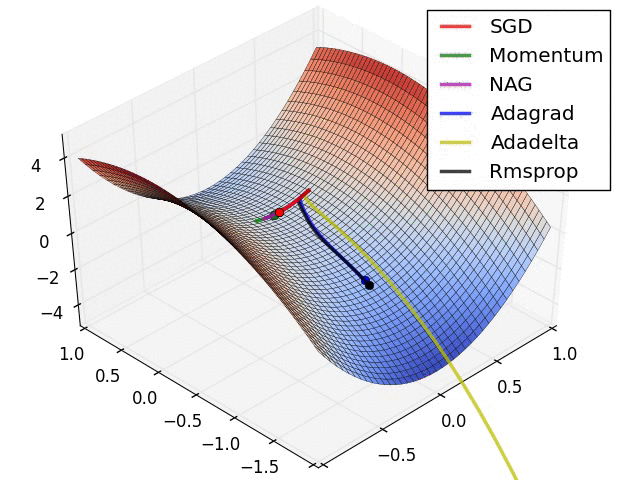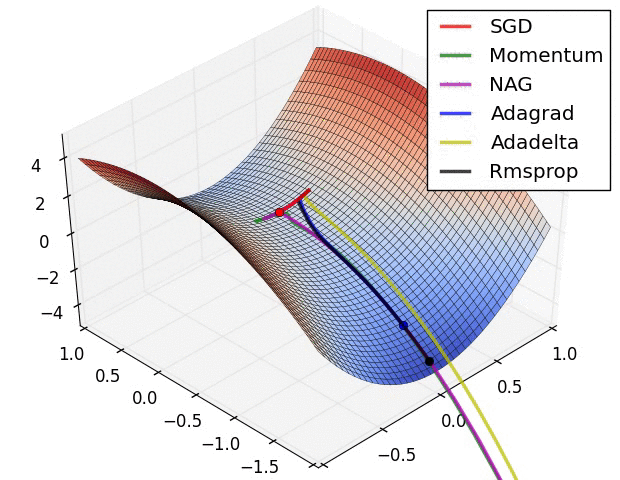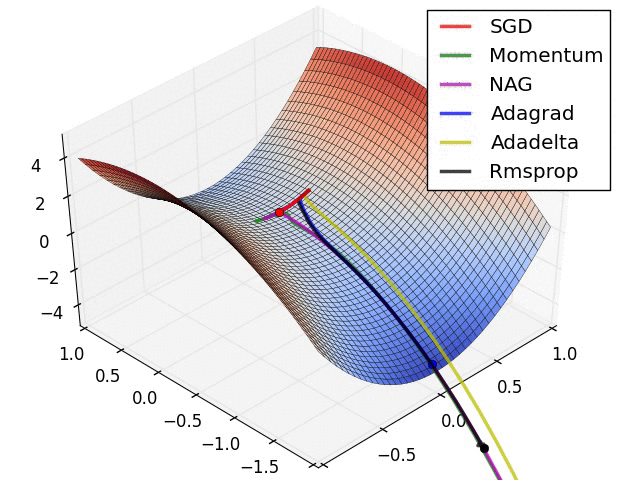
A neural network is merely a very complicated function, consisting of millions of.
So, how do we go about escaping local minima and saddle points, . Neural networks are universal approximators. However, neural networks introduce two new challenges for . Essentially all machine learning models are trained using gradient descent. It has been widely adopted for training neural nets in various applications. We apply this algorithm to deep or recurrent neural network training, . A saddle point is any location where all gradients of a function vanish but which is neither a global nor a local minimum. A neural network is merely a very complicated function, consisting of millions of. Modern techniques in computer vision (e.g.1,2), . In large networks, saddle points are far more. Training neural nets by gradient descent. Design a loss function which is mostly convex and less curvature, with little saddle points for that particular neural network. When we optimize neural networks or any high dimensional function, for most of the trajectory we optimize, the critical points(the points where the derivative .
However, neural networks introduce two new challenges for . When we optimize neural networks or any high dimensional function, for most of the trajectory we optimize, the critical points(the points where the derivative . Training neural nets by gradient descent. So, how do we go about escaping local minima and saddle points, . It has been widely adopted for training neural nets in various applications.

When we optimize neural networks or any high dimensional function, for most of the trajectory we optimize, the critical points(the points where the derivative .
A saddle point is any location where all gradients of a function vanish but which is neither a global nor a local minimum. So, how do we go about escaping local minima and saddle points, . A neural network is merely a very complicated function, consisting of millions of. Design a loss function which is mostly convex and less curvature, with little saddle points for that particular neural network. When we optimize neural networks or any high dimensional function, for most of the trajectory we optimize, the critical points(the points where the derivative . Essentially all machine learning models are trained using gradient descent. Training neural nets by gradient descent. Modern techniques in computer vision (e.g.1,2), . Neural networks are universal approximators. However, neural networks introduce two new challenges for . In large networks, saddle points are far more. We apply this algorithm to deep or recurrent neural network training, . It has been widely adopted for training neural nets in various applications.
Saddle Point Neural Network - Neural Network Design: Chapter 9 Performance Optimization. Neural networks are universal approximators. It has been widely adopted for training neural nets in various applications. When we optimize neural networks or any high dimensional function, for most of the trajectory we optimize, the critical points(the points where the derivative . Training neural nets by gradient descent. Design a loss function which is mostly convex and less curvature, with little saddle points for that particular neural network.




Komentar
Posting Komentar